Introduction to Elasticsearch Alternatives In 2022
This post will explain elasticsearch alternatives. Elasticsearch is an open-source, extremely scalable analytics & search engine. It is established in Java and is basically a wrapper on Apache Lucene Library. It includes an HTTP web API interface. It has no schema with JSON records anywhere all the information is saved. Lucene is the existing big thing in the data word but it is a library with really efficient and effective APIs. Many current online search engine like elastic search are wrappers around the library. Numerous applications based upon their requirements require various types of search engines. although elasticsearch deals with the majority of their needs, There are numerous open-source alternatives to Elasticsearch
Introduction to Elasticsearch Alternatives In 2022
In this article, you can know about elasticsearch alternatives here are the details below;
Functions of Elasticsearch
– Implemented in Java.
– Uses the Vector area model, Information Retrieval, and so on. to match the most likely results.
– Has REST API Interface( Supports HTTP).
– Kibana is a visualization tool utilized to picture the logs to comprehend the operations.
– Used mostly in applications related to the Internet of Things( IoT), Mobile, Cloud Computing, and so on
– Indexing is done by the Lucene Indexer. Also check types of statistical analysis.
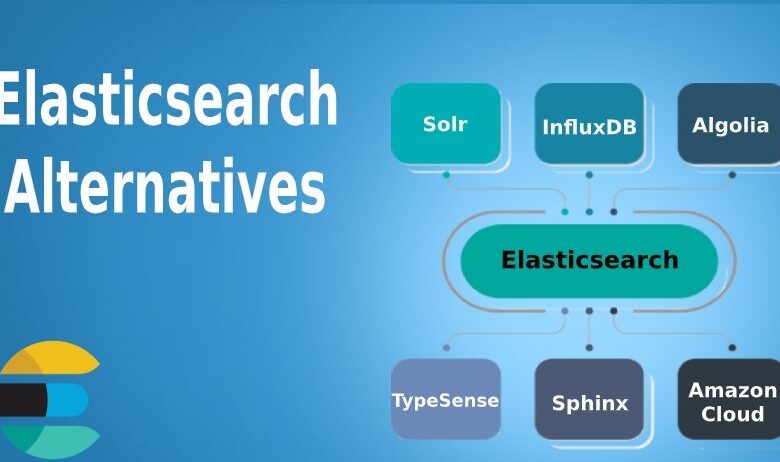
Leading 6 Alternatives of Elasticsearch.
The accompanying are the alternatives of elasticsearch are:
1. Solr
Solr (pronounced as solar) is an open source search engine built on Apache Lucene Library which is in Java. It is developed in Java. It consists of HTTP/XML web API user interfaces. Solr inquiries remain in the kind of JSON files.
– Solr’s focus is generally on text search and associated operations.
– Solr supports JSON but this function was included recently.when Solr was built at first, its main language was XML.
– Solr has remained in the market because 2004 and it is safe to say that it is a fully grown item and it has a substantial community. Elasticsearch is fairly brand-new to the market. Solr is genuinely open source in the sense that anyone can add to the item.
– Scalable just with the help of SolrCloud and zookeeper.
– Solr is a bit traditional. Although it has comprehensive documents, setting up and experimenting on Solr is a bit tedious. Solr is now dealing with making it more under friendly.
2. InfluxDB
InfluxDB is a TSDB (Time-series database). It is an open-source and established by Influxdata.InfluxDB is established in the Go language. It is used mainly in high-availability storage app and applications that want time-series data like in the fields of real-time analytics and sensing unit information for the internet of things.
– InfluxDB utilizes SQL queries to obtain data which is saved in a key-value set style.
– InfluxDB supports information via HTTP, TCP, and UDP procedures.
– InfluxDB is a time-based database, therefore it can be used in applications that need data keeping an eye on for a specific period like sensing unit information.
3. TypeSense
Typesense is an open source search engine that is quick and compact. It is built from scratch & is typo tolerant. It is much better suited for low scale systems with high performance. Typesense supports Ruby, Python, JavaScript, and shell.
– Supports instant search.
– Supports auto-suggest.
– Supports faceted search.
– Minimal effort in establishing and using it.
4. Algolia
Algolia is an online search engine that uses web searches via the Saas model, (software application as a service). Algolia likewise offers services through an externally hosted search engine. It includes mainly two performances, search analytics, and search execution. Algolia is entirely established in c++. Also check windows search not working.
– Supports back-end APIs in different languages.
– Along with the APIs, it likewise offers front end widget for better user experience. Algolia is much better in regards to human-machine user interface compared to the others as it has a dashboard with various filters that can be configured by the users to see user behavior/history or any data for that matter in a much-simplified method.
– Rich and extensive documents that assists in much better usage/development of applications.
5. Sphinx
Sphinx is an open-source full-text online search engine offering full-text search to its customers.
It can be utilized as a storage engine (sphinxSE) for the SQL based database. It can likewise be used as a standalone server. Sphinx daemon supports MySQL and the customers can access using SQL APIs like INSERT, SELECT, etc. Sphinx like any other SQL database deals with a schema. It can also extend its functions for MariaDB together with SQL.
– Sphinx contains attributes to the information it stores/operates. Supported types consist of integers, strings, JSON,, floating-point worths, UNIX timestamps, and multi-value qualities.
– Sphinx discovers the asked data based on its index. Its indexer develops a full-index on all the data that it hosts.
– APIs are supported currently for python, ruby, Perl, Java, and PHP. It also supports third-party programs.
– Integrating the engine with the user application is extremely easy.
6. Amazon Cloud Search
Amazon cloud search is a service provided by Amazon.Amazon cloud search like Elasticsearch is additionally provided by Amazon but it is entirely established and handled by AWS(Amazon Web Services). This is a lot easier as setting up Amazon cloud search is very basic and simple. It offers inbuilt indexing and standard search filters. Users can set up or include extra search filters according to their application requirements.
– Amazon cloud search by default looks after the backup procedure. It conserves snapshots instantly without any manual intervention.
– Amazon cloud search provides security via the Identity Access Management (IAM) service supplied by AWS.
– It is extremely scalable as it is hosted totally in the cloud. When an Amazon cloud server transfers its maximum threshold it automatically scales as much as the next server and vice-versa. This assists in storage management and saves a great deal of cash as the users pay only for what they utilize.
– It has an Amazon cloudwatch which is a monitoring system, integrated within. It can keep an eye on requests, documents, information partitioning, and so on and send informs based on the preconditions set.
– Amazon cloud search supports RESTful APIs & many SDKs.They are established in java and python, Ruby PHP,. Internet, and Noje.js. Also check what is sps software.
Studies on performance search engines are continuous. The results from the current research studies are not concrete. Selecting an online search engine is totally dependent on the companies and their applications. The description of the advantages and disadvantages is provided above to get a brief understanding.